FREAK算法来源2012年CVPR上的一篇文章FREAK: Fast Retina Keypoint,与ORB、BRISK算法类似,FREAK也是一种基于二进制编码的图像特征描述子,计算较快,对噪声鲁棒,具有尺度不变性和旋转不变性。此外,该算法还有一个突出特点就是受到人眼视网膜视觉机理的启发而提出。
在前面的博文中,介绍的BRIEF、ORB、BRISK算法都是基于特征点周围邻域像素点对之间的比较,形成二进制编码串作为特征描述子,这种描述方法计算速度快,且占用内存小,满足一些实时应用场景的需求。对于这类特征描述子,关键是确定邻域哪些像素点对进行比较,以及如何匹配。BRIEF算法中特征点邻域的像素点对是随机采样生成的,ORB算法是通过贪婪穷举的方法,在所有可能的像素点对中选取相关性较小的若干点对,BRISK则是采用平均采样的方法生成若干采样点。特征匹配方法通常都是采样Hamming距离来进行度量,由于是二进制编码方式,可通过异或操作快速计算。
特征点检测
FAST算法可实现快速检测图像特征点,而且对应有一个加速版本AGAST,因此在诸多特征描述子中,都是首先通过FAST算法搜索定位特征点,再加以描述。FREAK同BRISK算法类似,也是建立多尺度空间,在不同尺度的图像上使用FAST算法检测特征点。
采样模式
FREAK算法中采样模式接近于人眼视网膜接收图像信息的采样模型,如下图所示,人眼视网膜中,Fovea区域主要对高精度的图像信息进行处理,而Para区域则主要对低精度的图像信息进行处理。
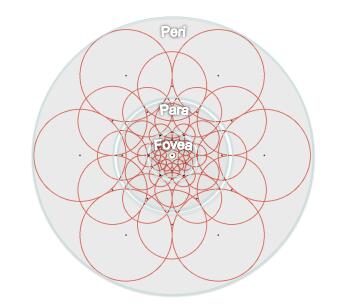
在FREAK的采样模式中,图中每一个黑点代表一个采样点,每个圆圈代表一个感受野,每个采样点需进行高斯模糊处理,以降低噪声影响,感受野的半径表示高斯模糊的标准差。这种采样模式与BRISK的不同之处在于,感受野之间存在重叠的区域;与BRIEF和ORB算法的不同之处在于,FREAK的采样点根据与特征点的距离远近,采用了不同大小的高斯核函数进行平滑处理。不同大小的感受野在人眼视网膜中也存在类似的结构,通过重叠的感受野,可以获得更多的信息,使最终的描述符更具独特性和可区分性。最终FREAK算法的采样结构为6、6、6、6、6、6、6、1,6代表每层中有6个采样点并且这6个采样点在一个同心圆上,一共有7个同心圆,最后的1表示特征点。
特征描述
FREAK算法同样采用二进制编码描述特征点,用$F$表示编码特征
$$F=\Sigma_{0 \leq a < N} 2^a T(P_a)$$
$$T(P_a) = \begin{cases} 1, I(P_a^{r_1}) > I(P_a^{r_2}) \\ 0, otherwise \end{cases}$$
式中,$I(P_a^{r_1})$表示采样点经过高斯模糊后的灰度值。
FREAK的采样模式中一共有43个采样点,可以产生$N = 43(43 - 1)/2 = 903$个采样点对,有些采样点对的编码值对特征描述并没有实际作用,反而会造成特征冗余,因此需要对特征的描述向量进行筛选,也就是降维。原论文中采用与ORB中类似的贪婪穷举的方法筛选采样点对。
- 对$M(M=50000)$个特征点建立一个$M \times N$的矩阵$D$,矩阵的每一行表示每个特征点的二进制描述符
- 对矩阵的每一列,计算其均值。由于$D$中元素是0/1分布的,均值越接近0.5说明方差越大
- 根据均值与0.5的距离从小到大,对矩阵的所有列重新排序(即按方差从大到小)
- 选取前$k(k=512)$列作为最终的二进制描述符
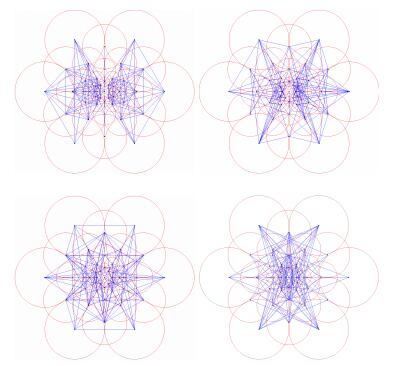
原论文中作者将得到的512个采样点对分成4组,每组128个,把这些采样点对进行连线,得到下图结果。作者发现,这四组连线中的第一组主要在外围,之后每一组连线逐渐内缩,最后一组的连线主要在中央部分,这与人眼视觉系统很相似,人眼视网膜首先也是通过perifoveal区域对感兴趣物体的位置进行估计,然后通过感光细胞更加密集的fovea区域进行验证,最终确定物体的信息。
特征方向
FREAK描述子自身的圆形对称采样结构,在某种程度上使其具有旋转不变性;采样的位置和半径随着尺度的变化使其具有尺度不变性;对每个采样点进行高斯模糊,也具有一定的抗噪性能;像素点的强度对比生成二进制描述子使其具有光照不变性。由此产生的二进制描述子可以用来进行特征匹配。但是在匹配之前,可以进一步描述特征点的方向信息。由于BRISK算法与FREAK算法对特征点邻域的采样模式相近,因此FREAK算法特征点方向的计算也与之类似。BRISK算法是通过计算具有长距离的采样点对的梯度来表示特征点的方向,FREAK算法则采用其中45个距离长的、对称的采样点计算其梯度,如下图所示:
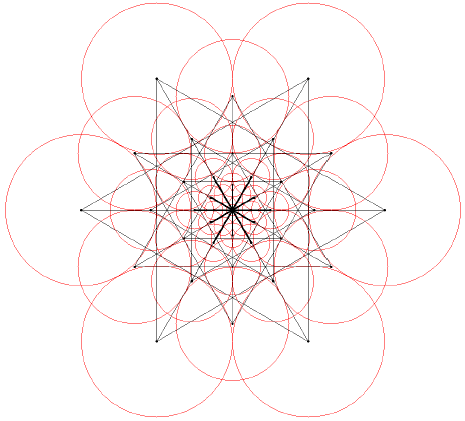
梯度计算公式为
$$O = \dfrac{1}{M} \Sigma_{P_o \in G} (I(P_o^{r_1}) - I(P_o^{r_2})) \dfrac{P_o^{r_1} - P_o^{r_2}}{||P_o^{r_1} - P_o^{r_2}||}$$
式中,$O$表示特征点局部邻域梯度,$M$表示采样点对的个数,$G$表示采样点对集合,$P_o$表示采样点对的位置。可根据梯度进一步求得特征点的主方向。
特征匹配
在特征描述中,得到了512bit的二进制描述符,该描述符的列是方差由高到低的排列,而高方差表征了模糊信息,低方差表征了细节信息,与人眼视网膜相似,人眼先处理的是模糊信息,再处理细节信息。因此,选取前128bit即16bytes进行匹配,若两个待匹配的特征点前16bytes距离小于设定的阈值,则再用剩余的比特位进行匹配。第一步匹配可以剔除掉90%的不相关匹配点,这种级联的操作在很大程度上提高了匹配的速度。
Experiment & Result
OpenCV实现BRISK检测与匹配参考代码
和FREAK(右)的对比实验结果")
从图示对比实验结果可以看出,ORB的特征点匹配效果要好。FREAK的突出特点在于将人眼视网膜的视觉机理引入了随机点对的采样模式,以及在特征匹配时采用Saccadic Search由粗到精的级联匹配方式,提高了特征匹配速度。
reference
- Paper: FREAK: Fast Retina Keypoint
- https://gilscvblog.com/2013/12/09/a-tutorial-on-binary-descriptors-part-5-the-freak-descriptor/
- http://blog.csdn.net/hujingshuang/article/details/47060677
- http://blog.csdn.net/lhanchao/article/details/52744514
- http://blog.csdn.net/yang_xian521/article/details/7732835